This is a Salesforce Data Cloud step-by-step guide that shows how to create a Vector Search Index from Knowledge Base Articles in a Core Salesforce Org and then Query that Vector Search Index from the external Query API. This post will be informative for any tech team looking to use the Salesforce Vector Database with external platforms such as ChatGPT Enterprise, Slack, or any preferred agentic middleware solution (n8n, Langchain, Flowise, Zapier, Make.com, etc). Here's the overall idea:
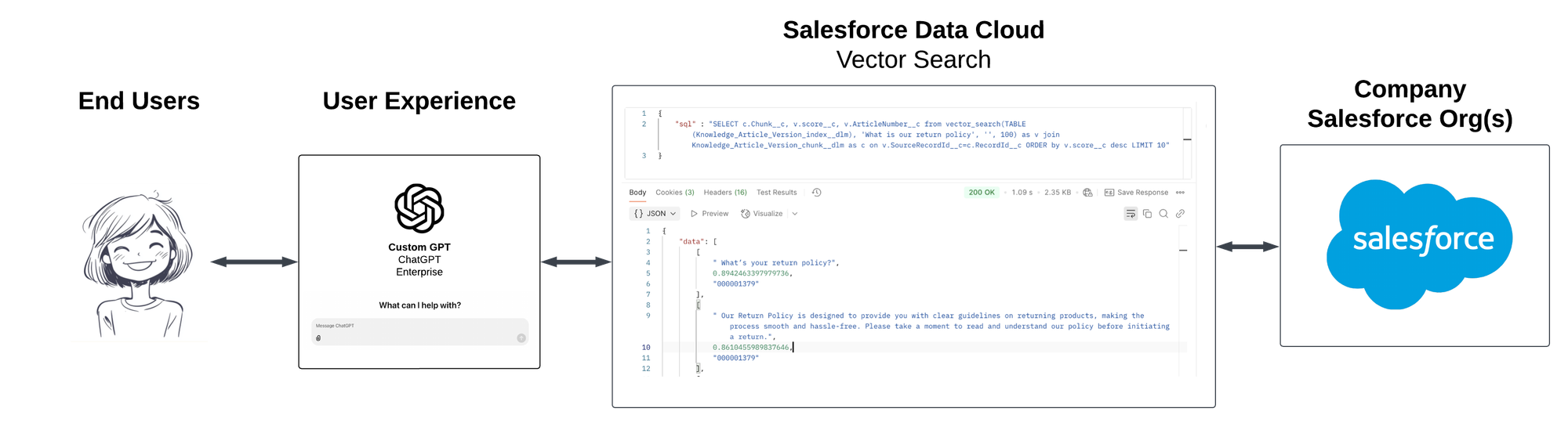
I aim to show each step needed from start to finish. There are a lot of steps involved, so if you're already familiar with how to set up Data Cloud, you may want to skip to the API section at the end.
Prerequisite: You will need access to a Salesforce Org and Salesforce Data Cloud in order to use the Salesforce Vector Database (Search Index). There are several free ways to do this. As an example, you could:
- Sign up for a Data Cloud Developer Edition
- Enable Data Cloud in your Enterprise Edition (EE) or above Production Org
- If you are an SI or ISV partner, you could create a Simple Demo Org (SDO)
I will use a Simple Demo Org (SDO) for this demonstration.
Step 1: Set up Data Cloud
First, you'll need to set up Data Cloud in your org. Assuming it has already been provisioned, you'll find the Data Cloud Setup link to the admin interface at the top right, under the standard Salesforce setup link.
1.1: Set Up Your Data Cloud Instance
Once there, you can enable data cloud from the Data Cloud Setup Home.
1.2: Salesforce CRM Integration
Next, you will need to connect your Core Org to Data Cloud. This is a little confusing if you're using Data Cloud from within your Core Org, but it works the same way as you connect other external Orgs (or other Data Sources). You need to set up the connection using Salesforce CRM Setup under the Integrations heading.
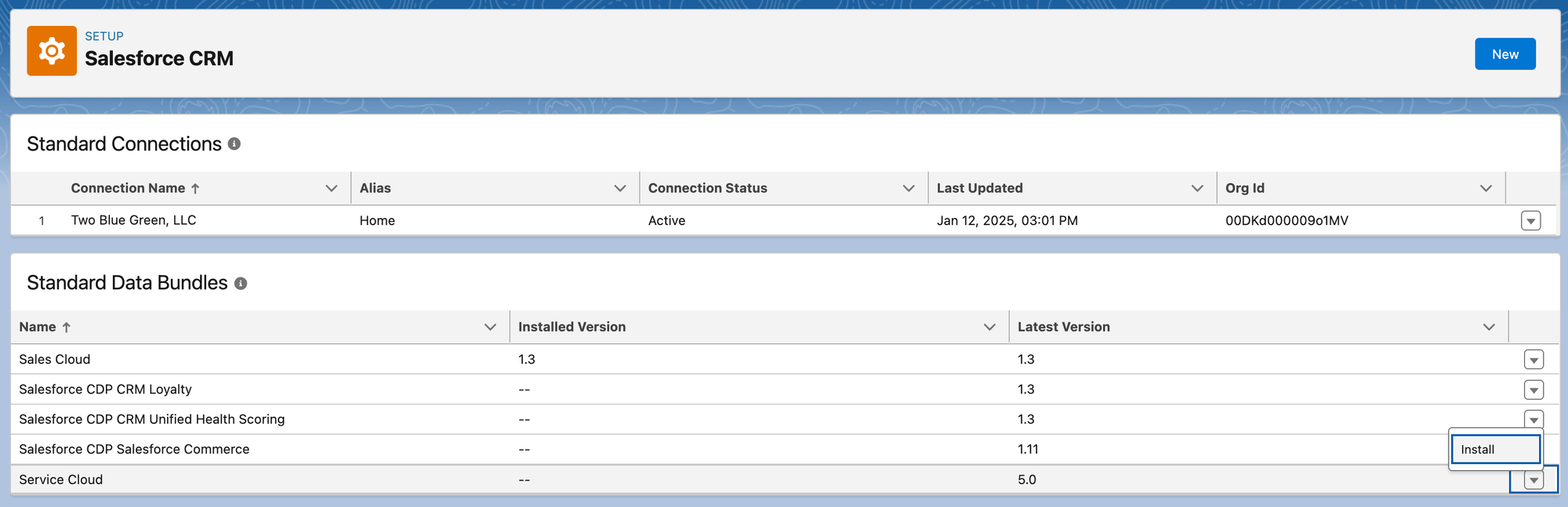
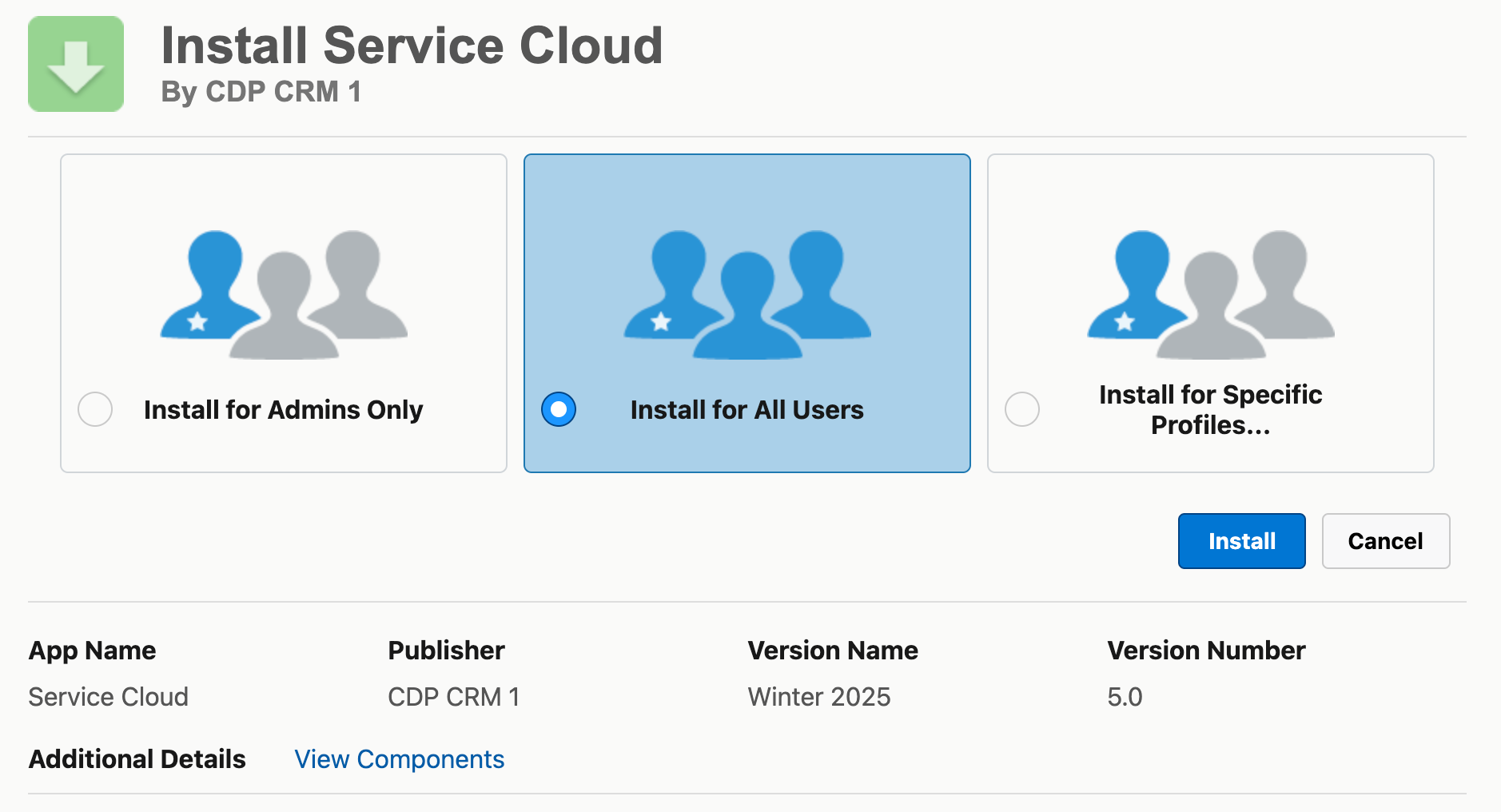
In this instance, you can see I've installed Sales Cloud (1.3) and am installing the Service Cloud (5.0) Data Bundle (bottom right). The CDP bundles listed haven't been installed. This brings up a standard Package Install page, and I'm choosing to install it for all users.
1.3: Permission Set Setup
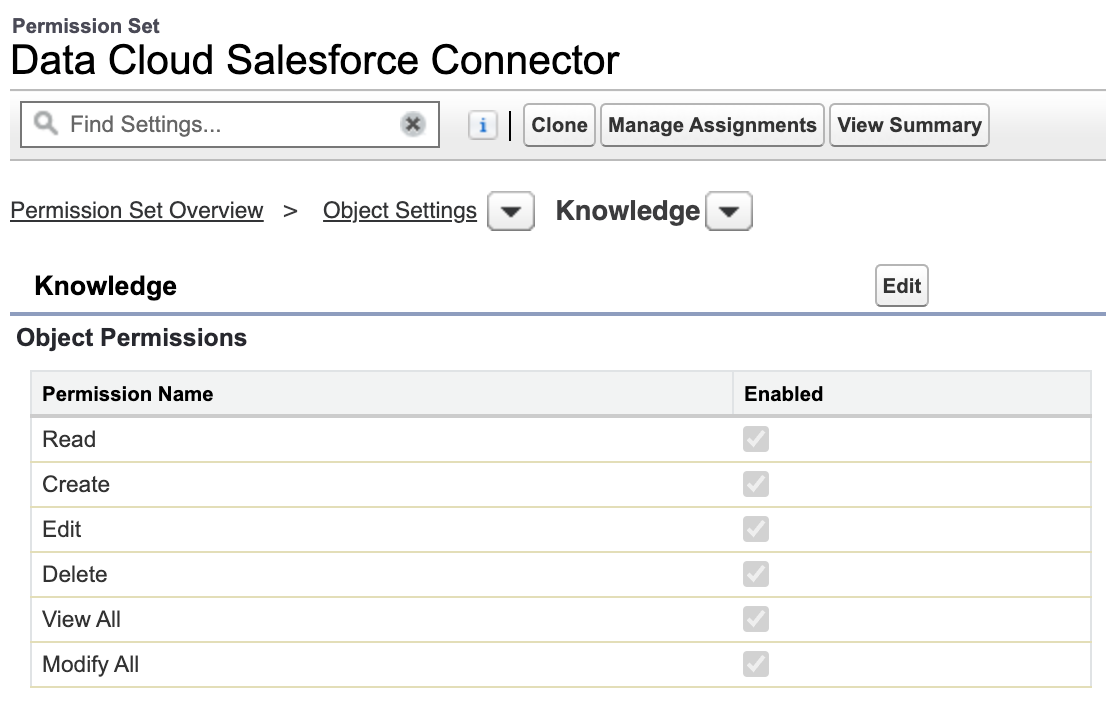
Lastly, since we will be setting up a Data Stream for Knowledge Articles, Data Cloud will need Read All and Modify All permissions on your Core Org Knowledge Article Objects. Data Cloud uses an integration user named Platform Integration User with a Permission Set named Data Cloud Salesforce Connector.
To provide access to Knowledge, you need to give access to the Data Cloud Salesforce Connector Permission Set for these Objects under the Permission Set Object Settings:
- CaseArticle__c
- KCSArticle_DataCategorySelection__c
- KCSArticle_ka__c
- KCSArticle_kav__c
- Knowledge
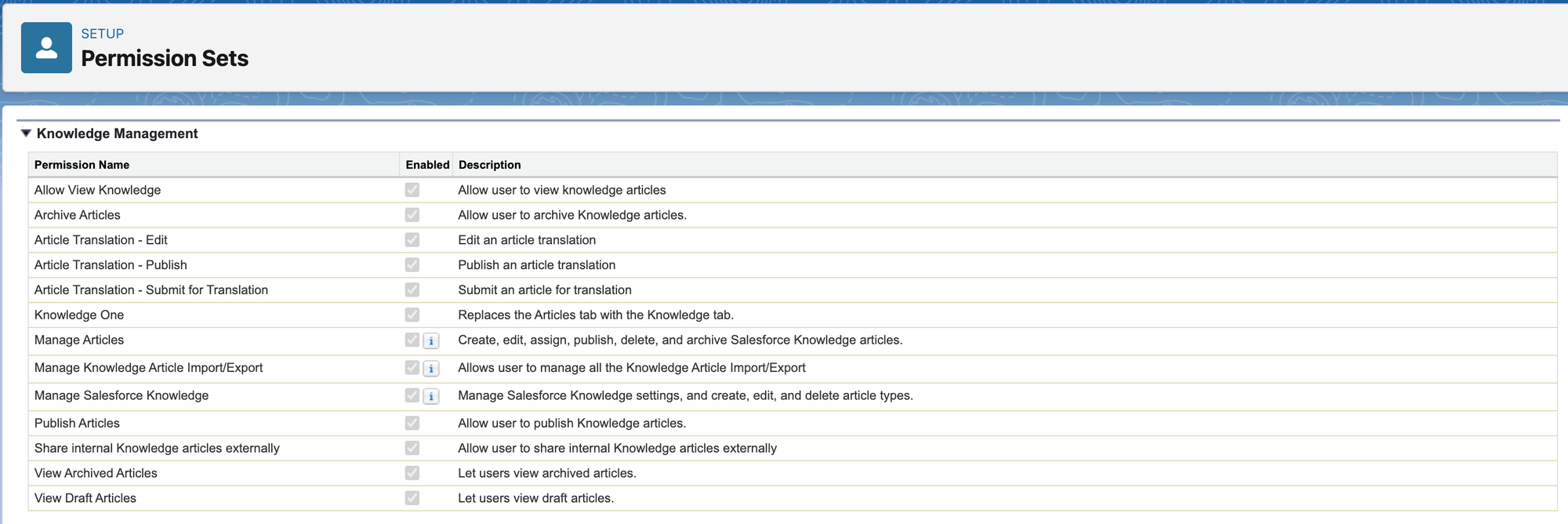
You also need to provide access to Knowledge Management in the Permission Set App Settings.
Step 2: Data Streams Setup
A Data Stream is a pipeline that brings data into Data Cloud for unification, analysis, and activation. In this case, you'll be bringing that Data into the Data Cloud environment in the Core Org that you're already in. But it could also be a separate Org, or multiple other Core Orgs, or other services entirely like Amazon S3, Airtable, Snowflake, or CosmosDB.
For these next steps, you will want to exit Data Cloud Setup, and select just regular old Data Cloud from the App Launcher for further... ah... well, setup. The first tab next to Home is Data Streams, which is where you should go next.
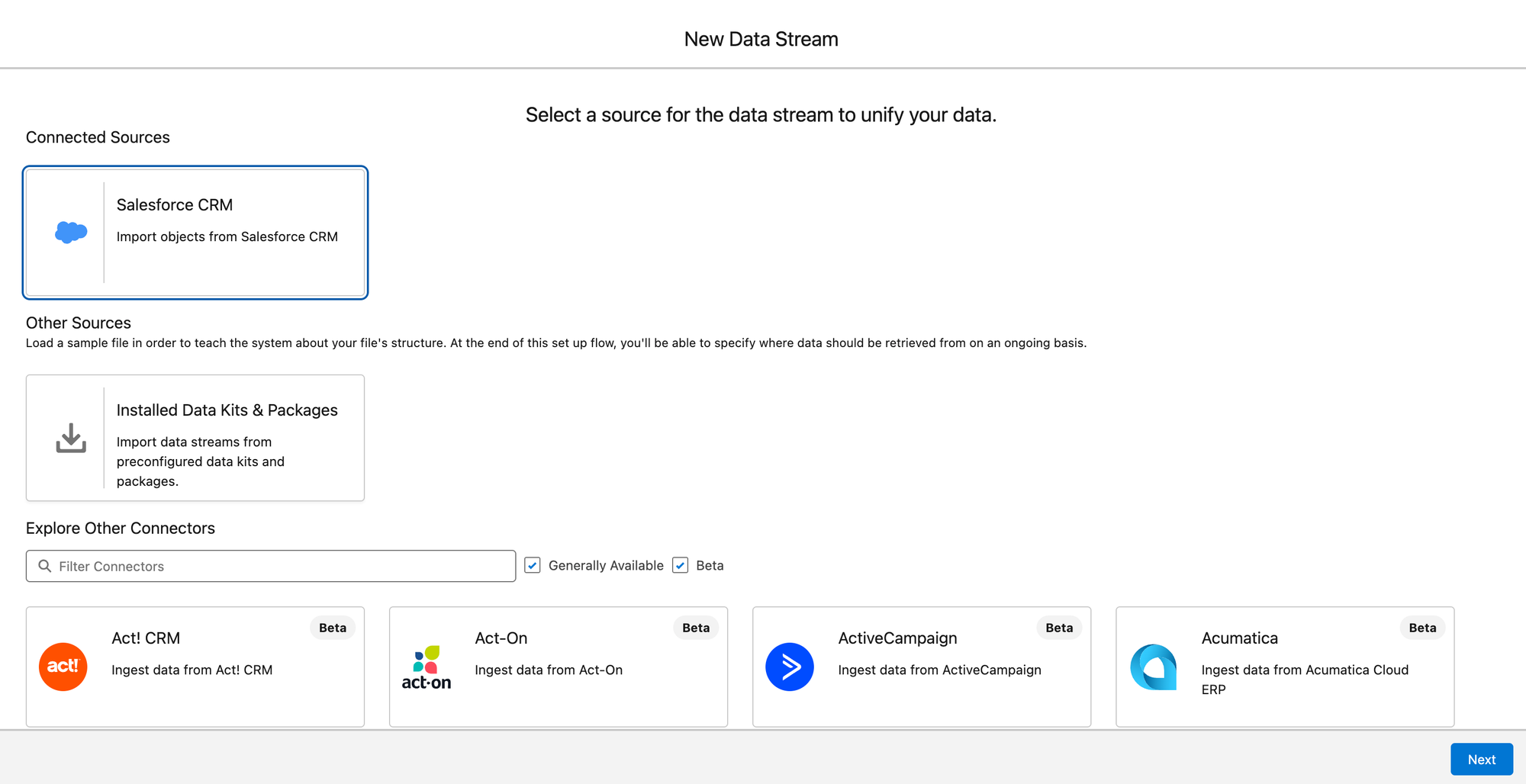
Next, we're going to select the Salesforce CRM org that we connected back in Step 1.2
After clicking Next, we'll be able to select the Knowledge Standard Data Bundle.
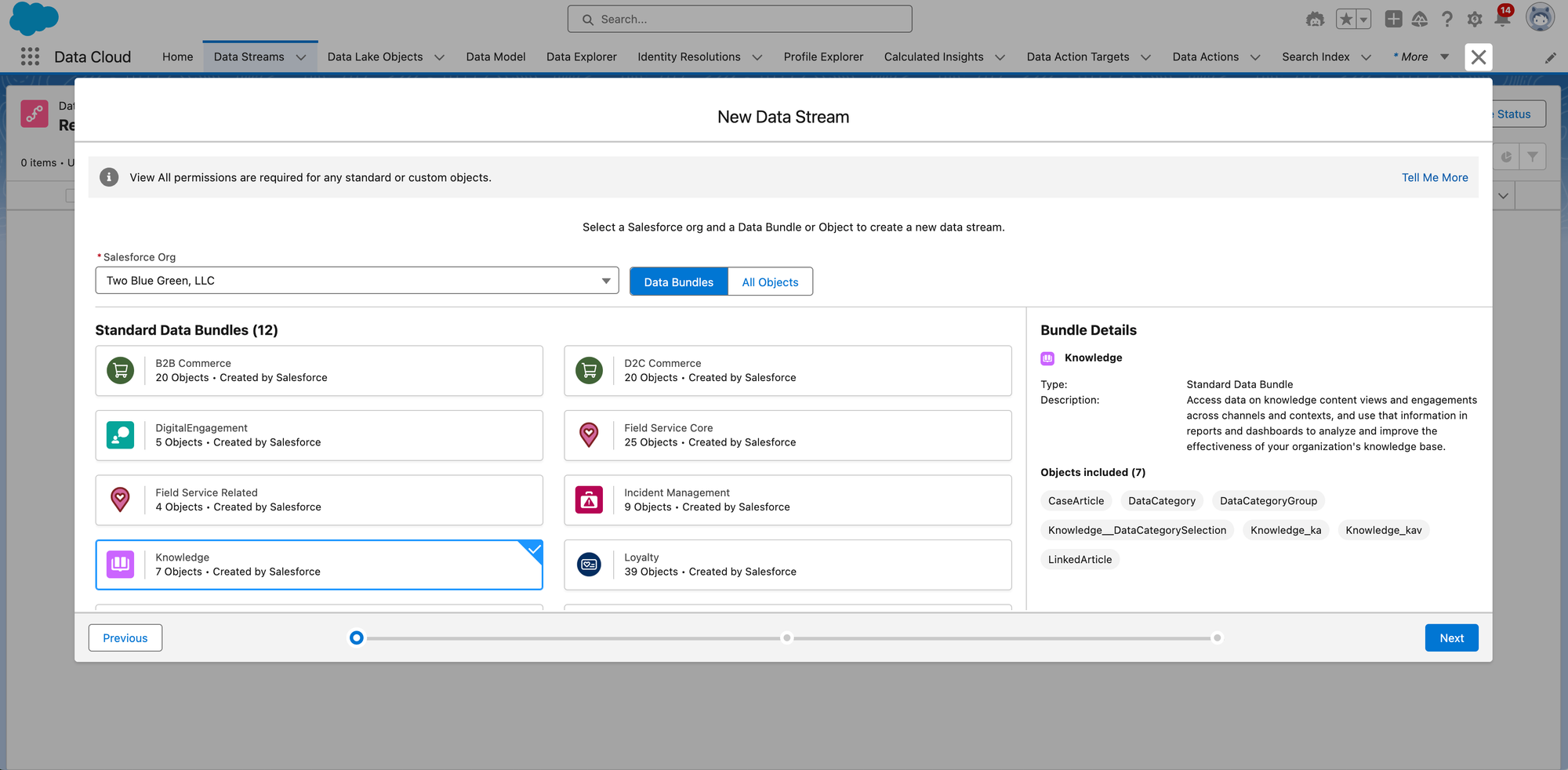
You can see the Knowledge bundle includes 7 Objects

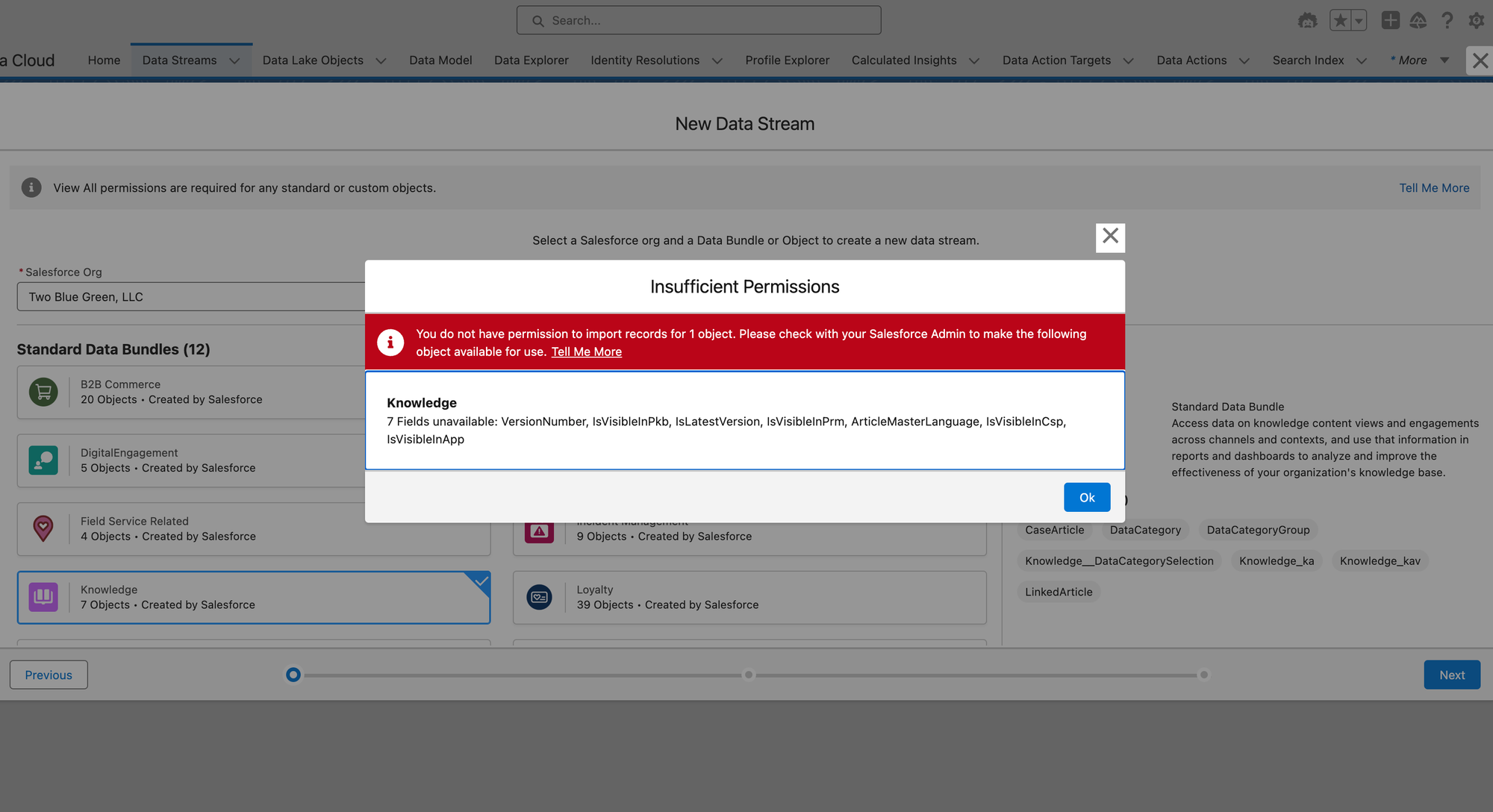
This is where you may get this error if you didn't get all of the Permission Set settings right above:
Insufficient Permissions: You do not have permission to import records for 1 object. Please check with your Salesforce Admin to make the following object available for use.
Knowledge: 7 Fields unavailable: VersionNumber, IsVisibleInPkb, IsLatestVersion, IsVisibleInPrm, ArticleMasterLanguage, IsVisibleInCsp, IsVisibleInApp.
If you get this error, make sure you've updated both the App Settings and the Object Settings for the Data Cloud Salesforce Connector Permission Set. See above for more info.
When you go to create your Data Stream, it won't include the actual Knowledge Article text by default. Since our goal is to create a vector search on the Knowledge Article text, we'll need to add that to the Data Stream by checking the box next to FAQ_Question_c and FAQ_Answer_c:
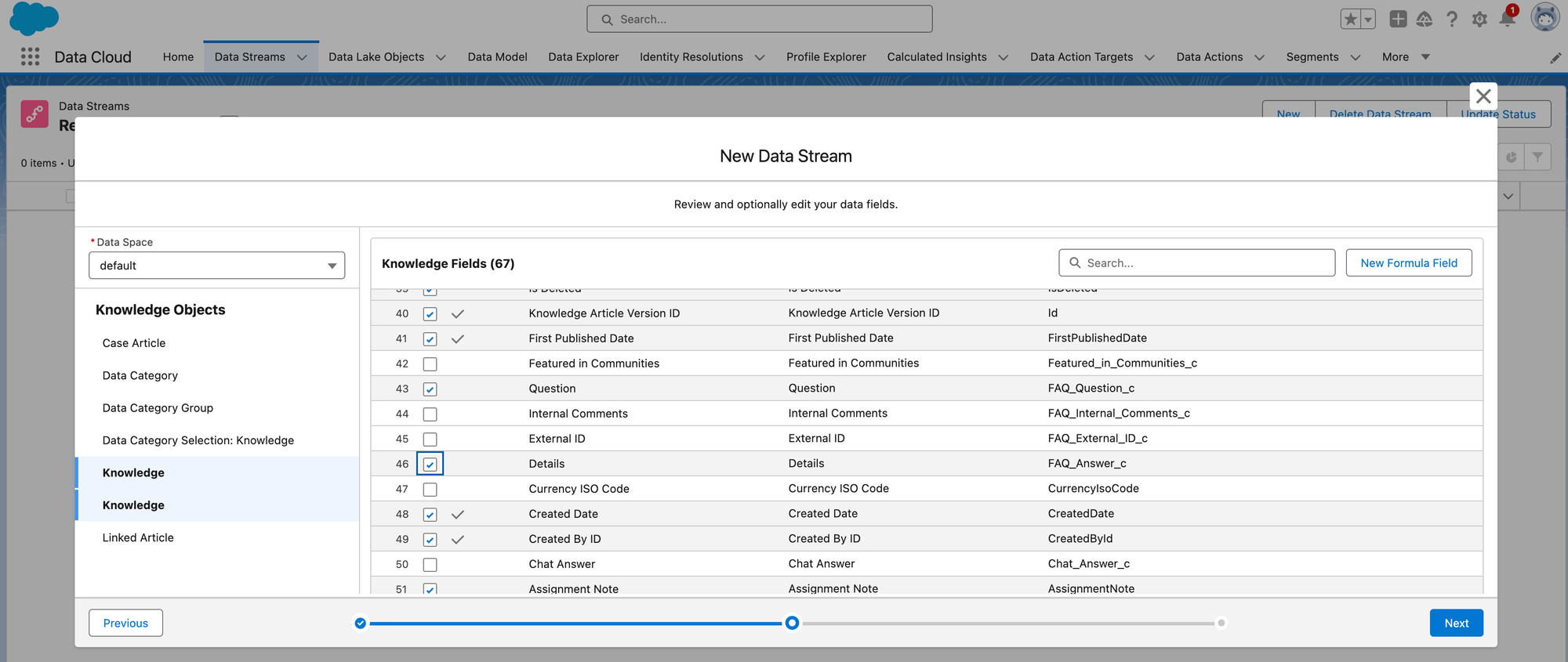
We'll leave these settings as their defaults before Deploying. The data model for Salesforce Knowledge is a little complicated, but the main thing to know for the purposes of this exercise is that the actual Knowledge Article text is contained in the KnowledgeArticleVersion Object, which is shown as Knowledge__kav_Home here ("kav" is short for Knowledge Article Version).
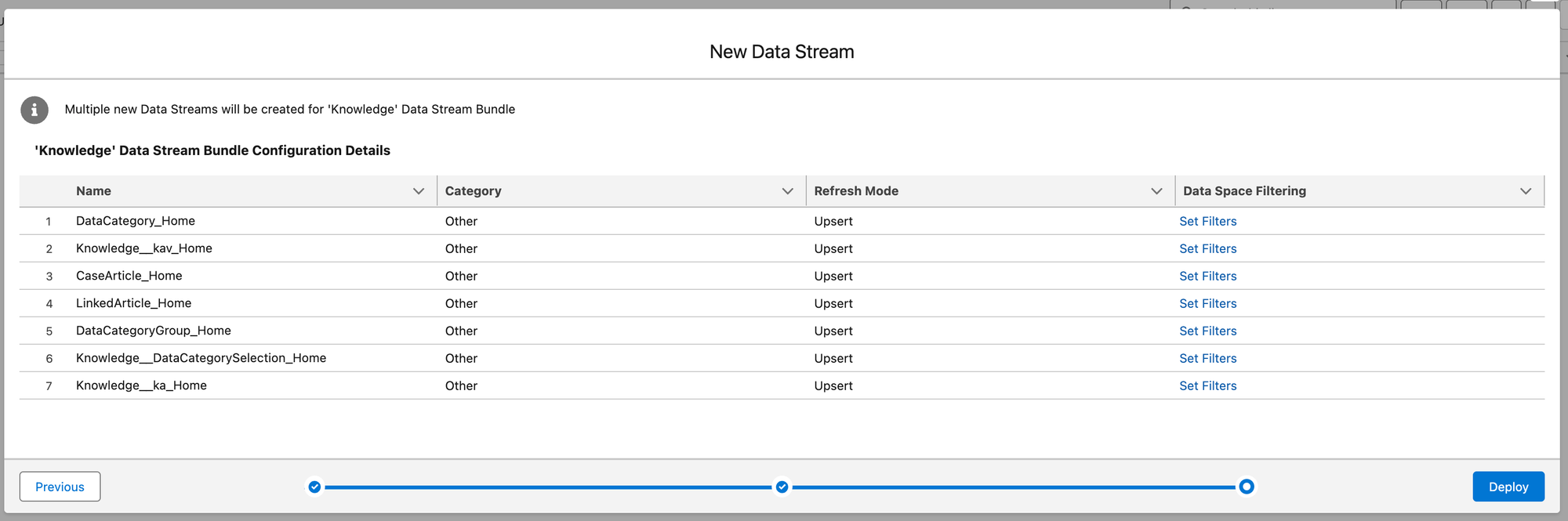
Once deployed, you'll see that you have some new Data Streams that have not yet been refreshed, meaning they don't have any data ingested yet.
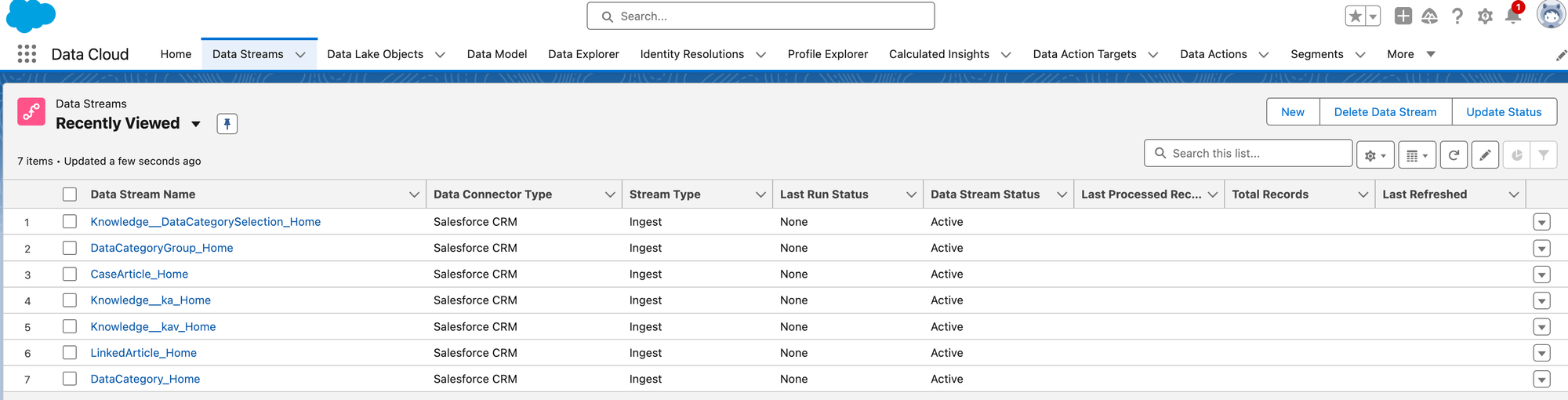
This process has also created corresponding Data Lake Objects and Data Model Objects for you:
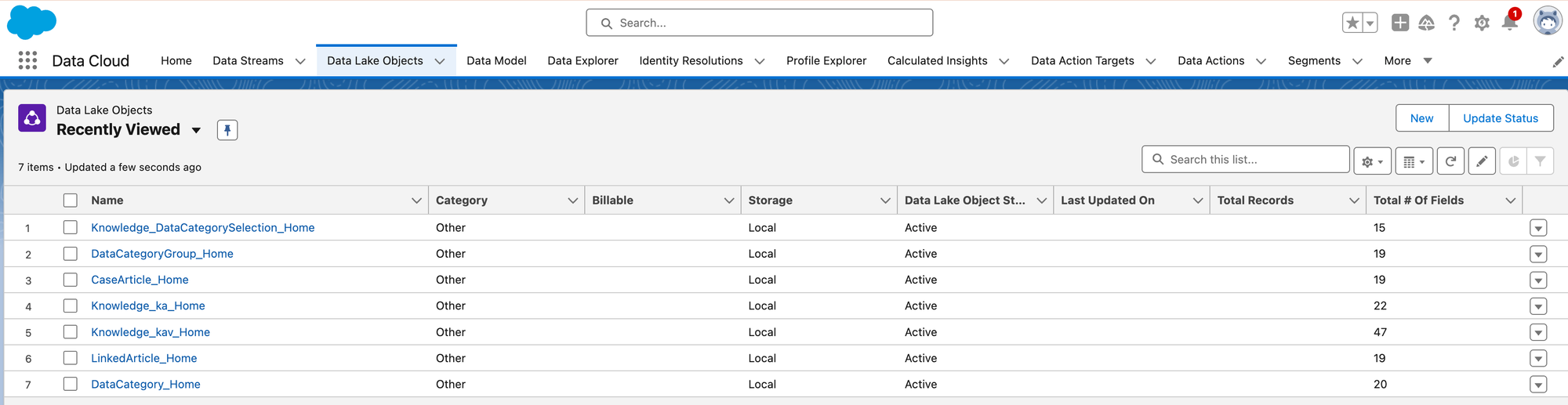
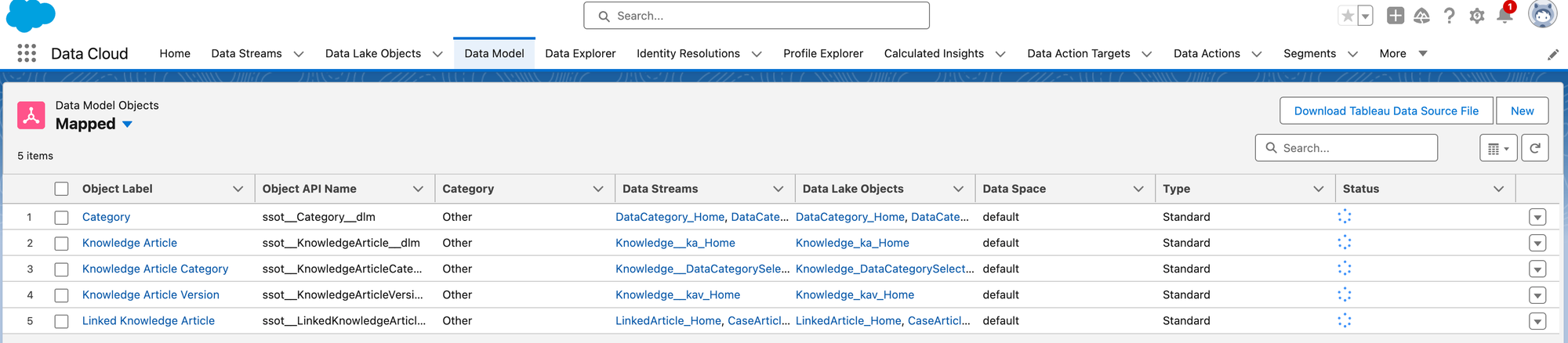
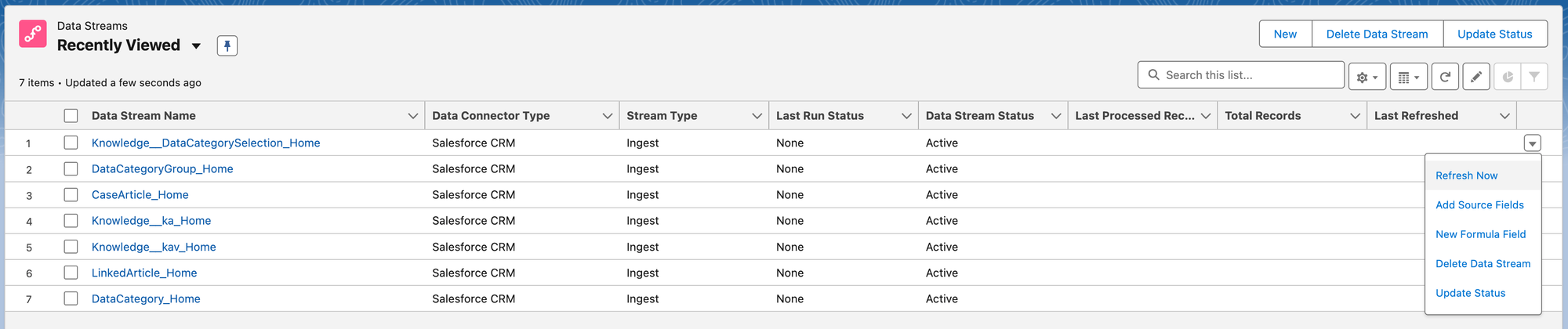
Data Streams need to be refreshed before you can do anything with them, so we'll go ahead and refresh each one:
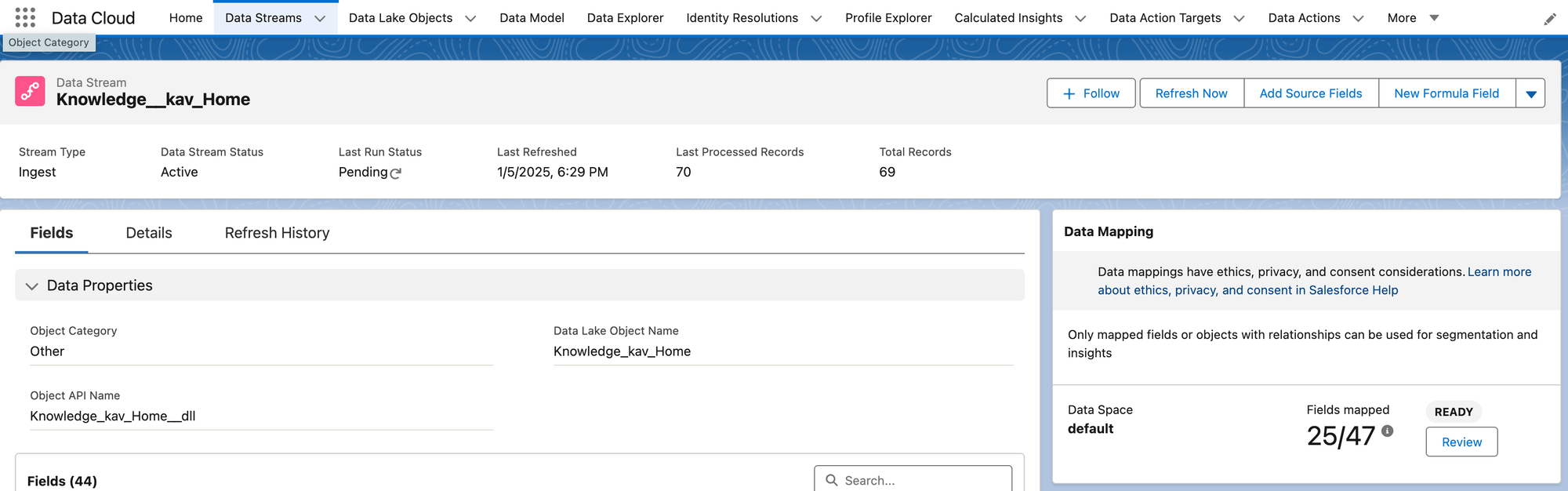
Lastly, the default Knowledge Data Bundle doesn't map the KB article content FAQ_Question__c or FAQ_Answer__c to the Data Model Object (DMO), so that's the last step we need to do. In the Knowledge__kav_Home Data Stream, click the Review button in the Data Mapping section.
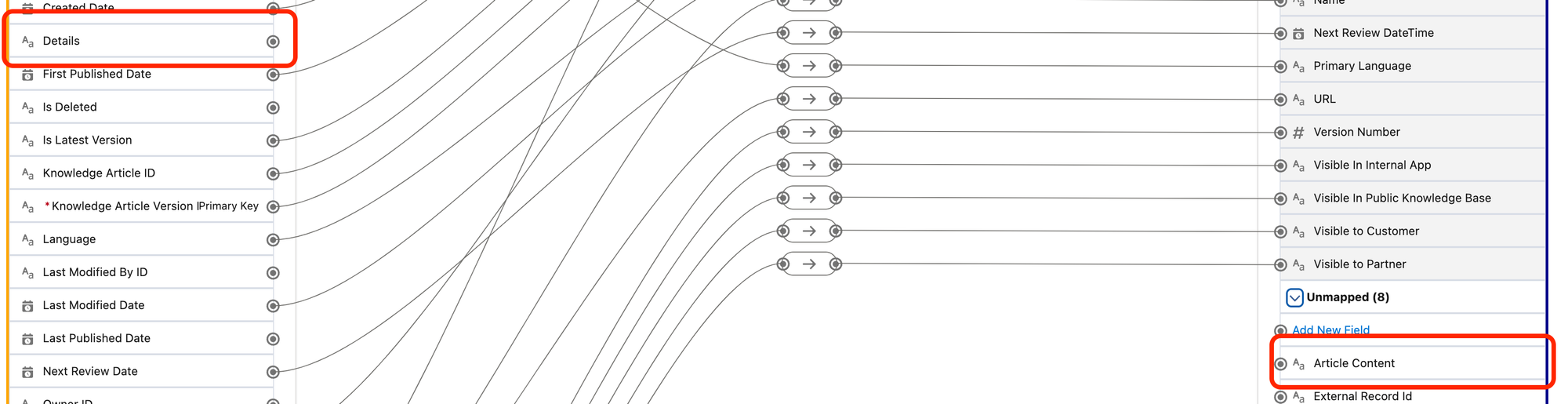
The field label for FAQ_Question__c is Question" and the field label for FAQ_Answer__c is "Details":

These fields aren't mapped by default, so we'll map Details to Article Content, and Question to a Custom Field (click Add New Field) that we'll name Article Question. Click the Save and Close button at the top of the page, and then the Refresh Now button from the Knowledge__kav_Home Data Stream page.
Step 3: Search Index Setup
The Search Index tab is where you will set up a Vector Search index for your Unstructured Data Lake Object (DLO). In the Data Cloud App, click the More tab to see a tab named Search Index. Click New, and you'll be presented with a dialog box like this. We will choose Advanced Setup.
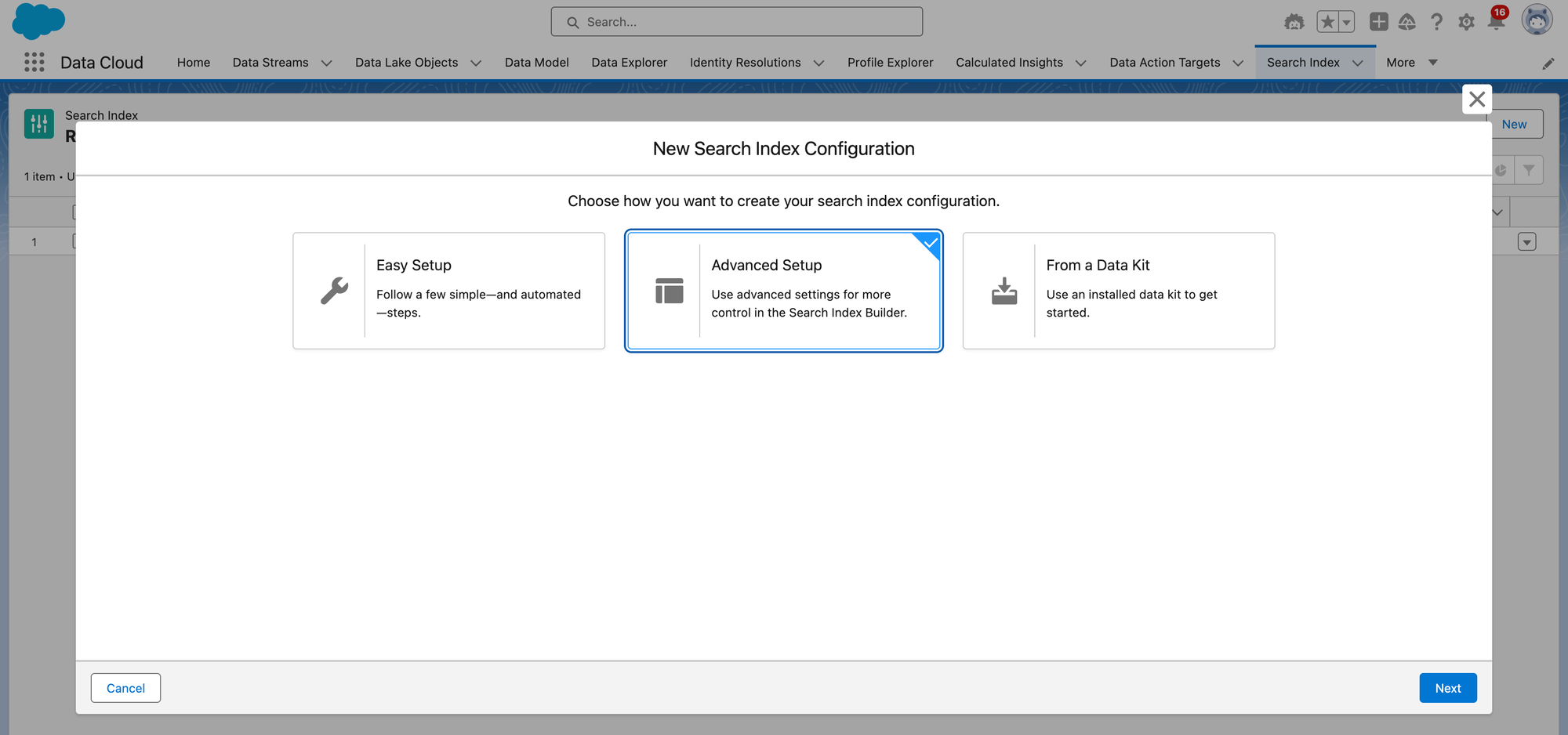
There are two types of Search Index available today. Vector Search and Hybrid Search.
Step 3.0: What is a Vector Database?
Either will work for the purposes of our demonstration, but here's a brief description of the difference:
A Vector Database takes long strings of text (a.k.a. "unstructured data"), breaks it up into smaller chunks (usually half a page to a page worth of text), and converts it into "Vectors" (a.k.a. an ordered list of numbers). Here's what a Vector looks like in Pinecone.io, a popular Vector Database.

A Vector Database makes it possible to do what's called "Similarity Search" or "Semantic Search", which is much more powerful for Generative AI Q&A than a typical Keyword search.
Here's an example: let's imagine you are searching through a database of clipart metadata looking for a picture of a pony.
- A Keyword Search will match images where the word "pony" is used exactly, but it won't find pictures of small horses, or other 4-legged barnyard animals.
- A Vector Search will correctly identify that a "pony" is similar to a "horse", which is also more similar to a "cow" than it is to an "apple". This sort of semantic understanding is what makes a Vector Database so powerful.
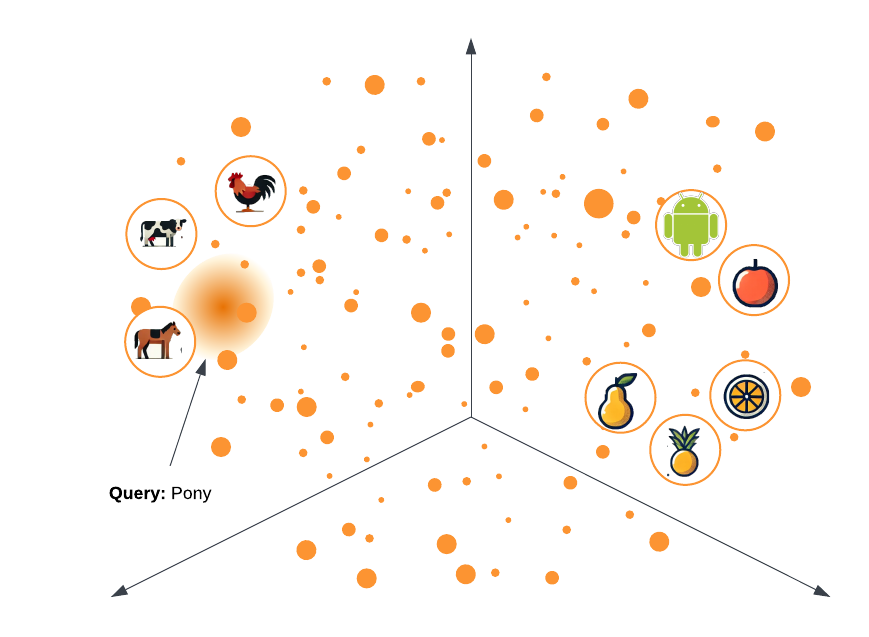
Vector Search is extremely powerful for this sort of semantic matching, but it's not great at other types of basic queries that computers are normally pretty good at like "how many apples are there?" or "what time is it". That's why the best option for any application is often a hybrid between Vector Search and a Keyword Search of additional metadata or data.
Step 3.1: Select the Search Type
Back to Salesforce Data Cloud, the Vector Search type does exactly what is illustrated above. We'll select Hybrid Search because it includes a Vector Search, but it also adds on some elements of Keyword Search in order to round out those shortcomings of a Vector Search.

Step 3.2: Chunking
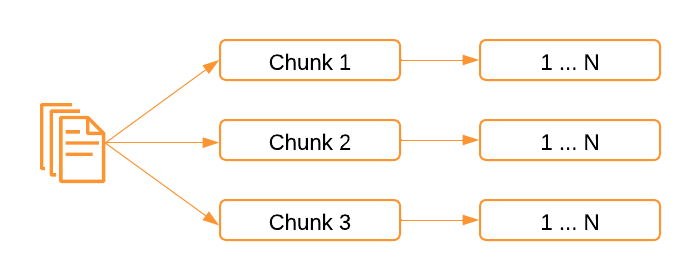
Vector Databases ingest data through a process called "Chunking and Embedding". If you think of vectorizing a long document, like a book, the first step will be to chunk it into smaller sections. There are a variety of different chunking strategies that try to keep contextually similar things within the chunk, but for the most part the idea is to create more manageable pieces of information before generating the vector embeddings.
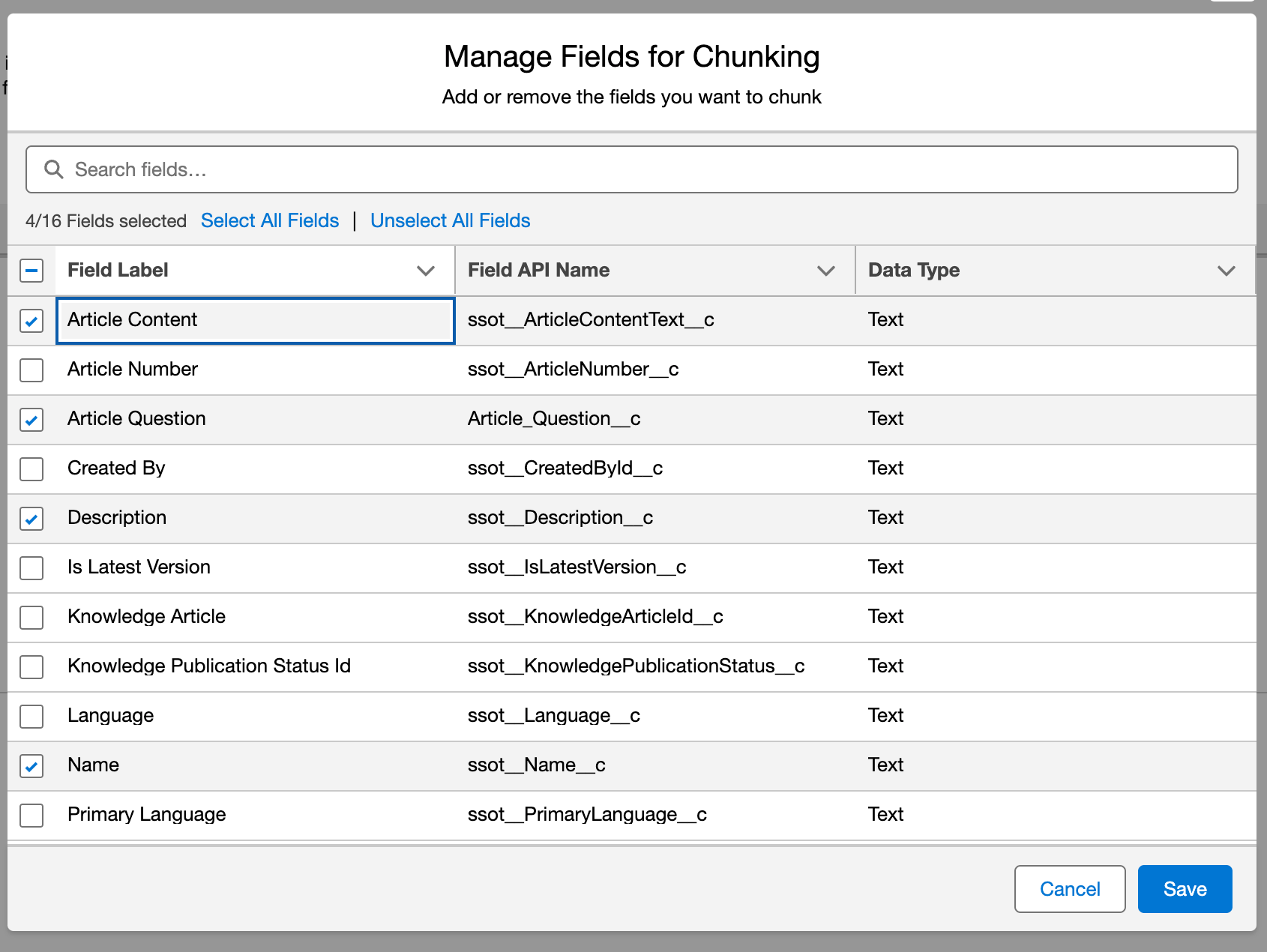
In this step, we'll select the fields that contain the most text for the Knowledge Article in order to use those for our Vector Embeddings
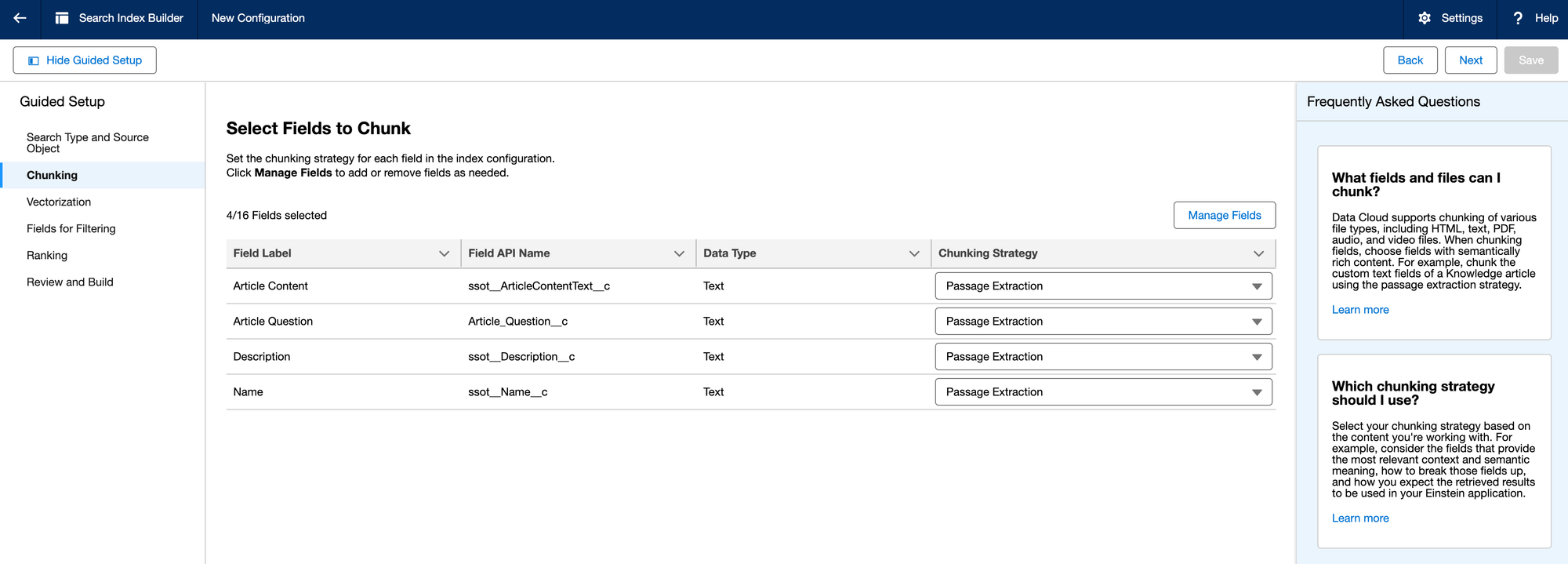
Step 3.3: Embedding
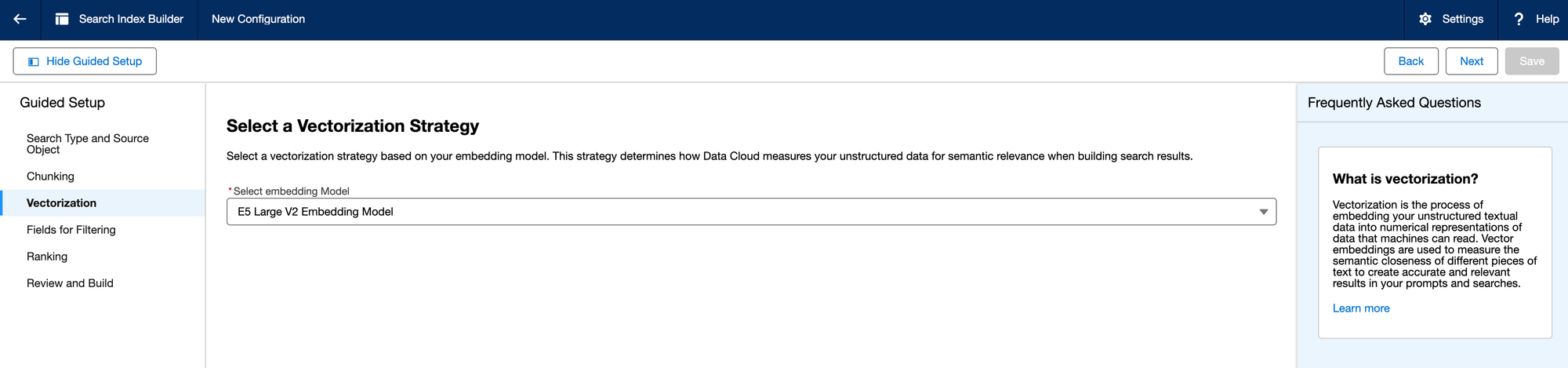
The next step is to pass these Chunks to an Embedding Model. This uses a Large Language Model (LLM) to generate vector "embeddings" to store in the Vector Database. Each of the LLM vendors have options for vector embeddings (OpenAI, Anthropic, etc).
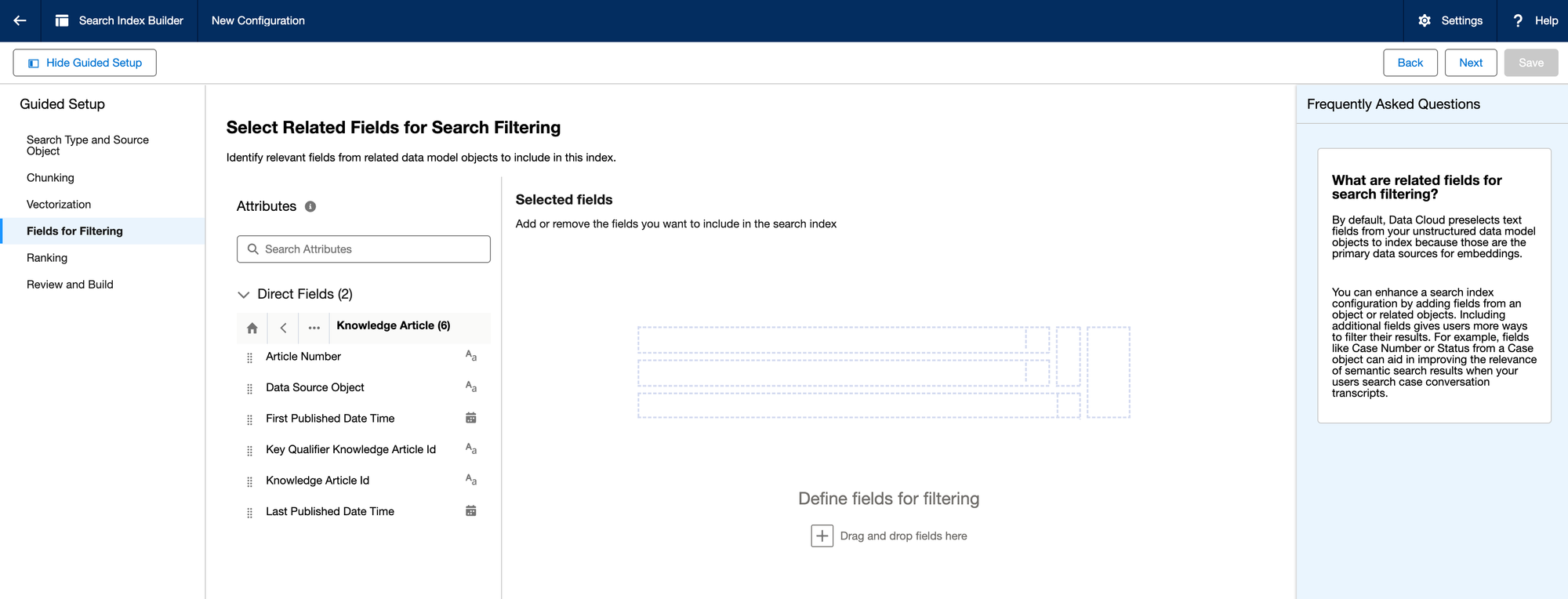
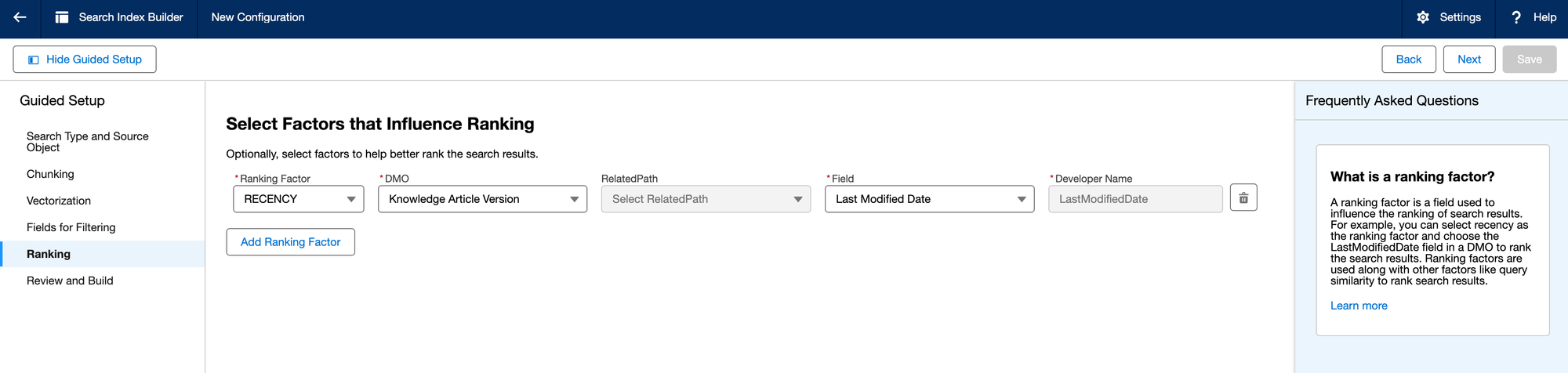
Step 3.4: Filtering and Ranking
In this step you can control the search results a bit by adding filters and ranking the results.
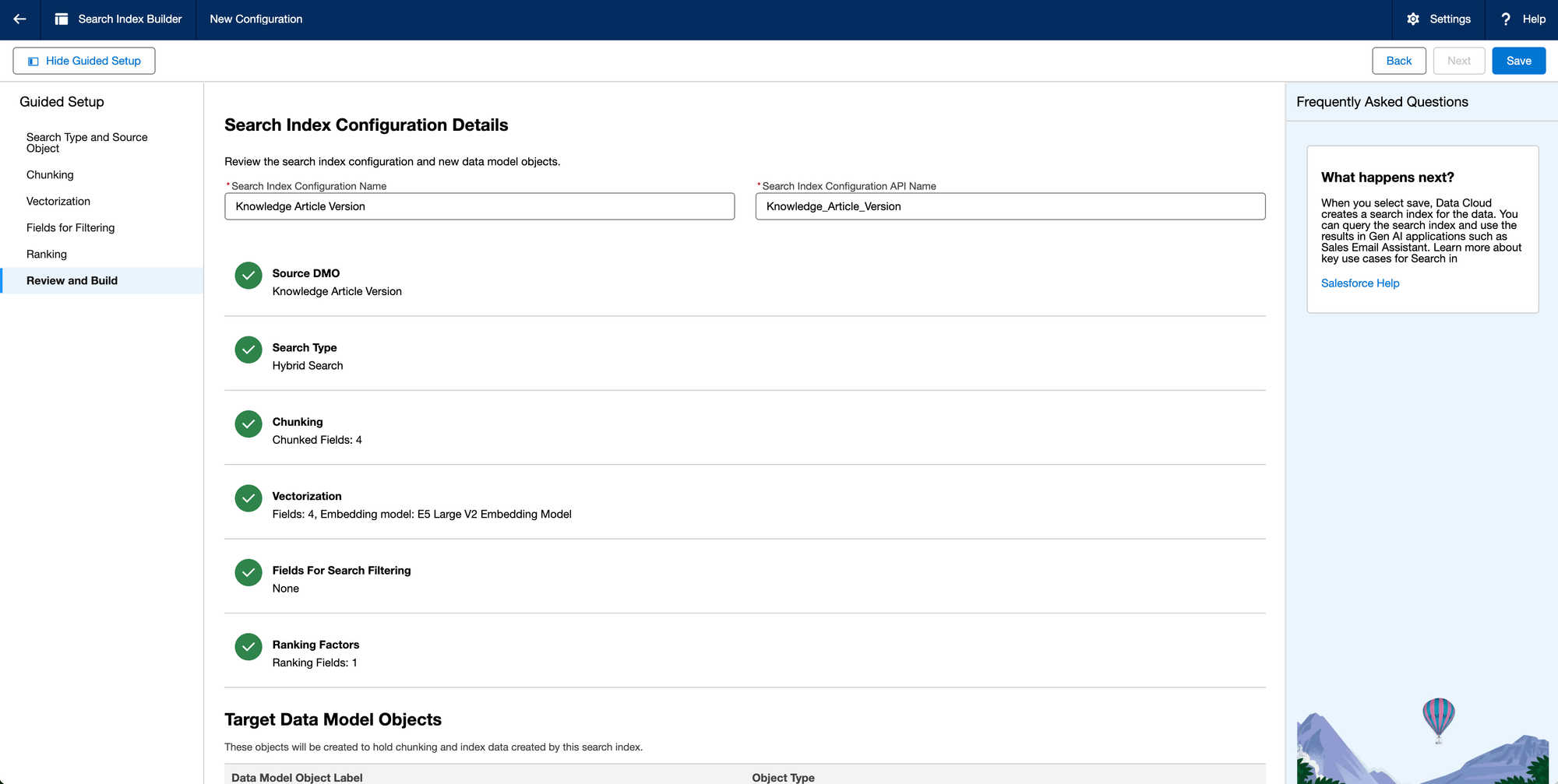
Step 3.5: Review and Build
That's it. Just click Save at this point and let it run.
Step 4: Query API
Now that you've built a Vector Search Index from Data Cloud, we've finally gotten to the goal of this article! In this step, we will show how to query Vector Index from an external source using the Query API. We'll be using Postman in order to do this, so start off by signing up for a free account at https://www.postman.com/
Step 4.1: Postman Setup
To show how to use the Query API, we'll start with the Postman Data Cloud API interface published by salesforce-developers. Just follow the instructions on Postman to fork it into your own environment with the "Fork the collection using this button".

Step 4.2: Postman Authentication with Data Cloud
Postman makes this step very easy. From the Overview tab of the Salesforce Data Cloud APIs page, click on the Authentication tab, scroll down and click the "Get new Access Token" button, and then "Use Token" from the dialog box that comes up next.
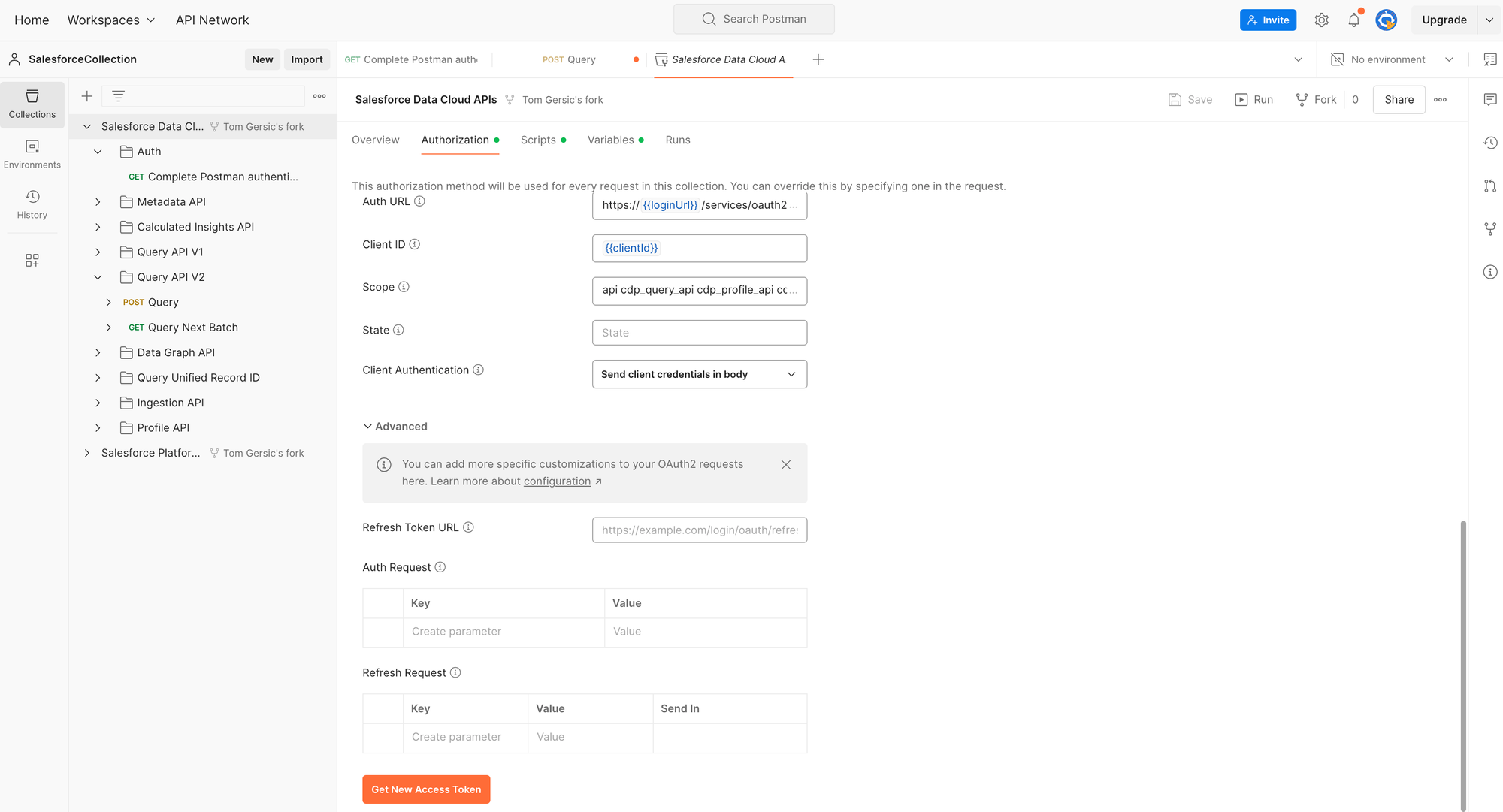
You can then Complete the authentication by clicking Send in the script under the Auth folder:
Step 4.3: Postman Authentication with Data Cloud
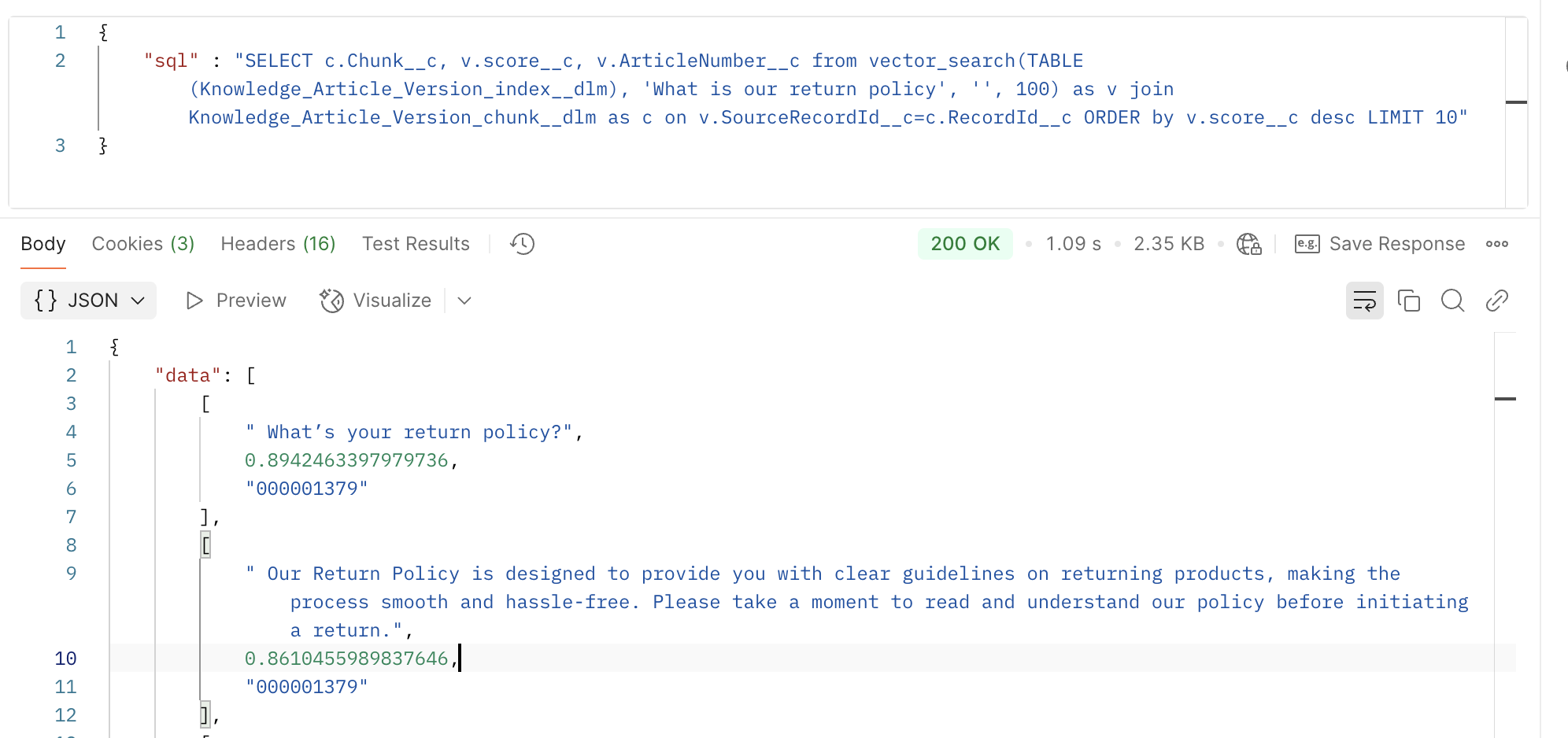
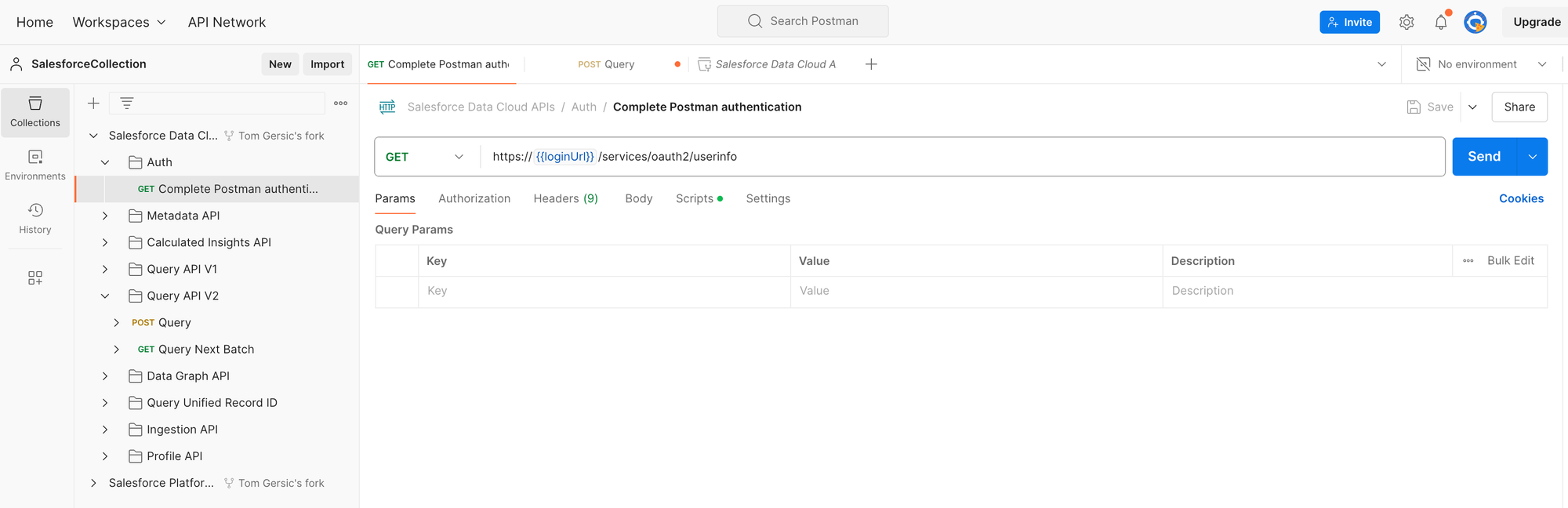
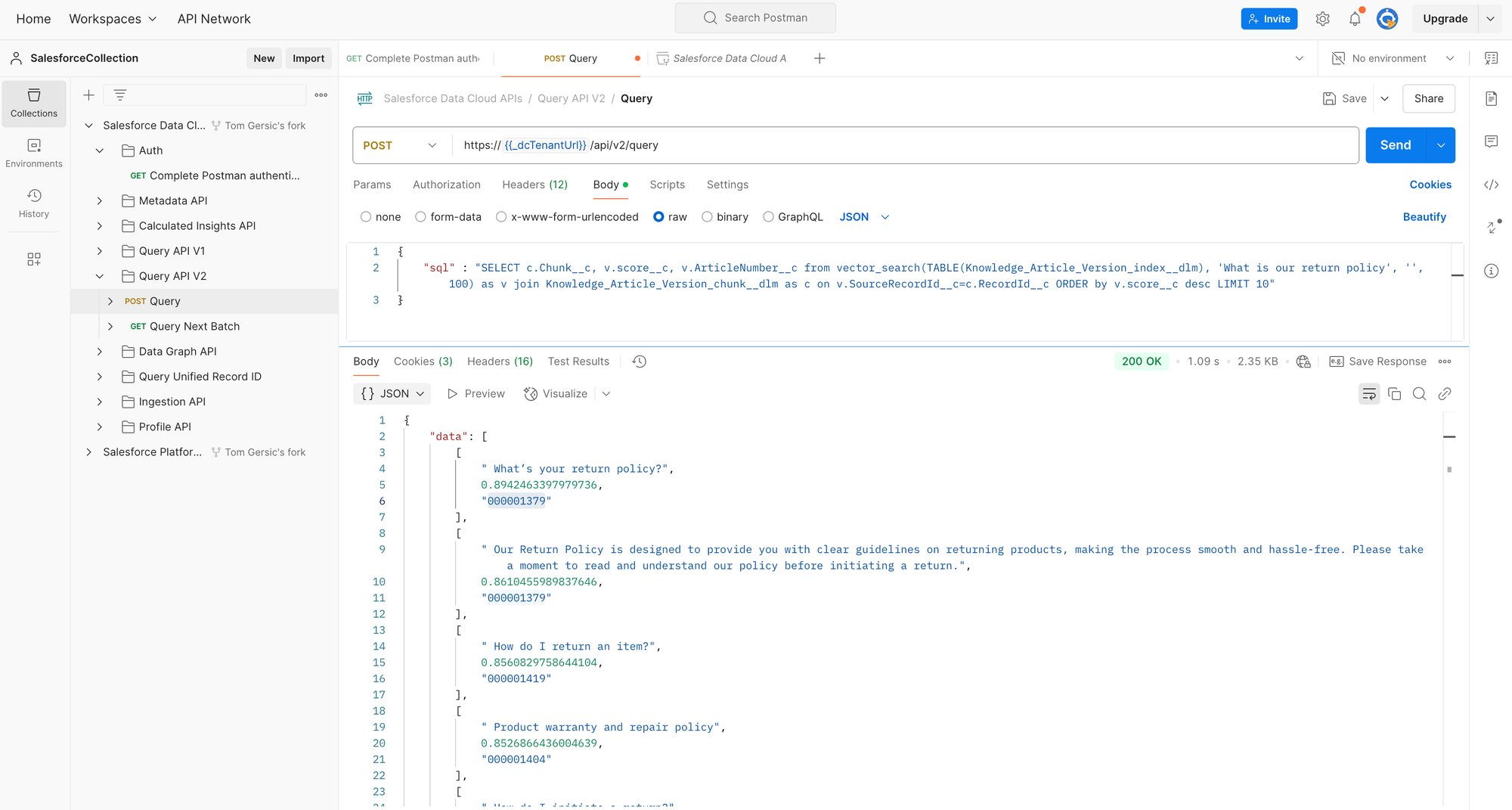
Next we will complete a Vector Search with the Query API V2. Here's an example SQL query for: "What is our return policy".
SELECT c.Chunk__c, v.score__c, v.ArticleNumber__c from vector_search(TABLE(Knowledge_Article_Version_index__dlm), 'What is our return policy', '', 100) as v join Knowledge_Article_Version_chunk__dlm as c on v.SourceRecordId__c=c.RecordId__c ORDER by v.score__c desc LIMIT 10
With this, you can see the vector search results from the API
Summary and Next Steps
This article was a step-by-step guide that shows how to set up Data Cloud from scratch, ingest Knowledge Articles into an Unstructured Data Model Object (DMO) using a Data Stream, and then create a Vector Search Index from that unstructured data. From that point, we've shown how to query this from an external source using PostMan in order to authenticate and query the Data Cloud Query API V2.
The next step from this point will be to show how to build a middleware that can connect a User Experience like ChatGPT Enterprise with this Vector Search API. Stay tuned for more.



