The generative AI market is expanding at a staggering pace, but building solutions that actually work for users requires more than chasing shiny features. It demands a commitment to continuous improvement rooted in real data and feedback.
Why RAG Alone Isn’t Enough
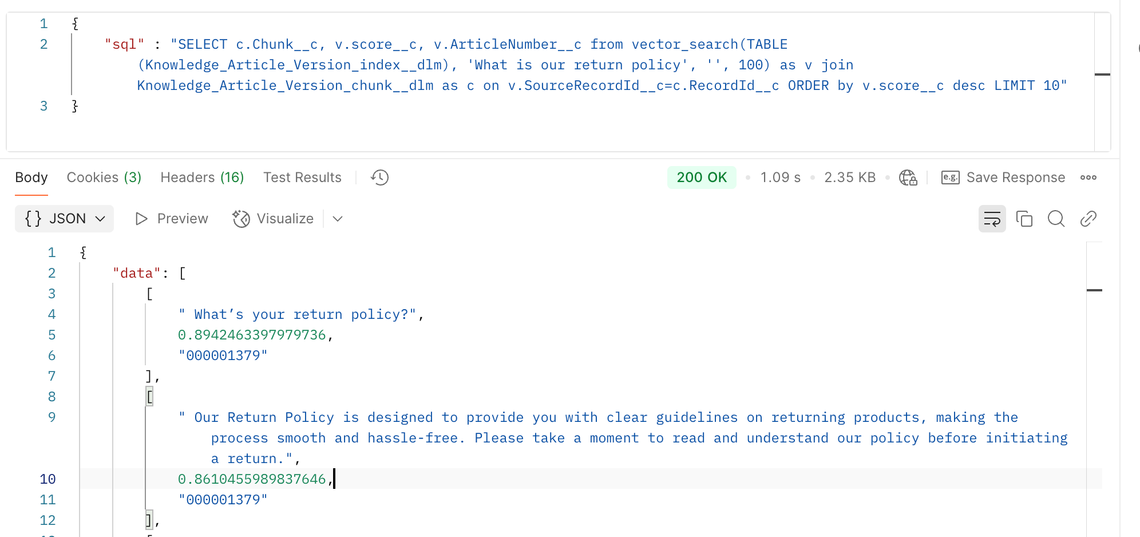
Retrieval‑augmented generation (RAG) is a central paradigm for grounding language models in external knowledge: embed a user query, retrieve relevant documents, and pass them to an LLM to generate an answer . In a customer‑support chatbot, this lets you serve answers drawn from up‑to‑date support articles rather than the model’s static training data.
RAG solves part of the problem, but not all of it. Even the best vector search sometimes returns irrelevant chunks or misses key details. Basic RAG pipelines run linearly – retrieve once, generate once – and hope for the best. When the retrieval misses, the model can hallucinate or guess at an answer. Worse, there’s no memory of past mistakes: the next customer asking a similar question will hit the same blind spots.
Why I’m not fine‑tuning (and that’s okay). In a production enterprise stack, fine‑tuning sounds attractive but usually works against you. It ties you to a specific snapshot of a base model, so when vendors ship better foundation models (e.g., GPT‑5 → GPT‑5.x), you don’t get the upgrades for free—you inherit a re‑tuning and re‑validation project. Add the hidden costs: curating and de‑identifying training data, running legal/privacy reviews, building eval sets, standing up MLOps to host and monitor custom weights, and planning safe rollbacks. For most customer‑support scenarios you get more lift, faster, by “teaching not training”: improve retrieval (chunking, rerankers, hybrid search), enrich the knowledge base, add tools (calculators, APIs), and codify corrective instructions and few‑shot exemplars. You keep upgrade agility—when the next model lands, you swap it in and your RAG + tooling benefits immediately—without paying the fine‑tune tax. Save fine‑tuning for narrow, stable needs (strict format/style, uncommon jargon) where a measured lift justifies the ongoing overhead.
From Static Pipelines to Agentic RAG
Self‑reflective and agentic RAG systems add a layer of reasoning on top of retrieval and generation. Rather than blindly using the first documents that pop out of the vector store, the model asks itself whether those documents are good enough, whether it should rephrase the question, or whether it needs to search another data source . State machines or graphs let you encode these decisions: if the retrieved docs aren’t relevant, re‑write the query and retrieve again. This feedback loop happens during the user’s request, improving the immediate answer without altering the model weights.
Measure What Matters
If you want your agent to keep improving over time, you need to measure its performance. That means logging every question, the context retrieved and the answer generated, and scoring them on dimensions that matter. RAGAS is an open‑source framework designed for this. It provides retrieval metrics like context relevancy and context recall to tell you how well your retriever pulled the right chunks and generation metrics like faithfulness and answer relevancy to tell you whether the model used those chunks accurately and stayed on topic. Unlike traditional NLP metrics, these scores correlate better with human judgments and they can be computed reference‑free on production data . RAGAS also defines context precision, the proportion of relevant chunks in the retrieved context, and provides methods to compute it with or without human references.
Below is an illustrative example of how four core RAGAS metrics might look on a real support chatbot. Faithfulness and answer relevancy are high, but the retriever’s context precision lags, indicating we need to tune the vector store or re‑chunk our documents.
Triggers for async improvement (typical thresholds)
| Signal | Trigger idea |
|---|---|
| Faithfulness < 0.6 or user thumbs‑down | Kick off human/async research agent; consider corrective instruction generation. |
| Context recall < 0.5 | Missing coverage → KB gap; propose new/updated doc + re‑index. |
| Context precision < 0.4 | Retriever noise → re‑chunk, reranker, filters, hybrid (keyword + vector). |
| Answer relevancy < 0.6 | Revisit prompting (intent detection/clarification) or agent routing. |
Be sure to adjust these thresholds after you see your own distribution.
Practical options for async data storage
- Persist inside LangSmith/Langfuse: Stores full run traces and dataset/eval results. You can attach a RagasEvaluatorChain so RAGAS scores are logged alongside each run and analyzed later.
- Use your own store (such as Snowflake, Databricks, etc): Keeps a source of truth for async workflows, joins with product telemetry, and enables offline analysis at scale.
What to store (so you can drive async fixes later)
Run metadata
run_id,timestamp,env(prod/staging),session_id,user_id(if applicable)- Model & prompt:
model_name,model_version,system_prompt_id,prompt_version - Graph/chain:
graph_version,tool_calls, latency, token/cost
Retrieval snapshot
retriever_name,embed_model,embed_model_versionchunk_size,top_k, filters, query-rewrite flagsretrieved_doc_ids(+ doc version or content hash) to reproduce the run
Inputs/outputs
question,final_answer, optionalground_truth(if you have one)- User signal: thumbs up/down, follow-up count, escalation flag
RAGAS scores (store as numeric fields)
faithfulness,answer_relevancy,context_precision,context_recall(and any others you use). Context precision measures the proportion of relevant chunks among retrieved contexts.
Evaluator provenance
ragas_version,metric_config_id(so you know how the score was produced)
This schema lets you: (a) filter low-faithfulness runs for human/agent follow-up, (b) pinpoint retriever issues (low context precision/recall), and (c) re-evaluate after fixes.
Observability: LangSmith vs. Langfuse
Logging and scoring is only useful if you can analyze the results. LangSmith and Langfuse provide observability platforms that trace each run, store your evaluation scores and let you drill into failures. LangSmith offers a platform to create datasets, run evaluations and visualize results. Its evaluation framework uses RAGAS metrics under the hood and lets you continuously add examples from production logs. Langfuse plays a similar role but is fully open source. It stores traces and spans and allows you to score them using metrics like faithfulness, answer relevancy and context precision. Langfuse’s analytics let you segment and search traces to identify low‑quality responses and drill down into specific user segments .
Closing the Loop: Dynamic Context and Corrective Feedback
Monitoring alone doesn’t fix anything; you need to act on the feedback. Instead of treating RAG as “retrieve some documents,” we view it as “construct whatever context maximizes the chance of a correct answer.” The context can include document chunks, tailored instructions and even few‑shot examples. By evaluating how much each piece of context improves or hurts the answer, the system can prioritize high‑utility contexts and learn which ones to avoid .
The key is to close the loop: after every interaction, store the query, the answer and the outcome (user feedback, evaluation scores). When an answer is poor, generate a corrective instruction that would have prevented the error, and store it as a special context item. During future queries, retrieve these instructions along with documents so the model avoids repeating the mistake. Likewise, when an answer is excellent, store it as a candidate few‑shot example. Over time the system builds a library of high‑utility instructions and examples, dynamically injected into prompts to guide the model. This adaptive retrieval makes the model behave as if it had been trained on new data without actually fine‑tuning.
Blueprint for Continuous Improvement
Below is a conceptual blueprint that brings these pieces together for a customer‑support chatbot. It starts with a simple RAG pipeline and then layers on instrumentation, evaluation and improvement. The arrows indicate the feedback loop that helps the system get smarter with each interaction.
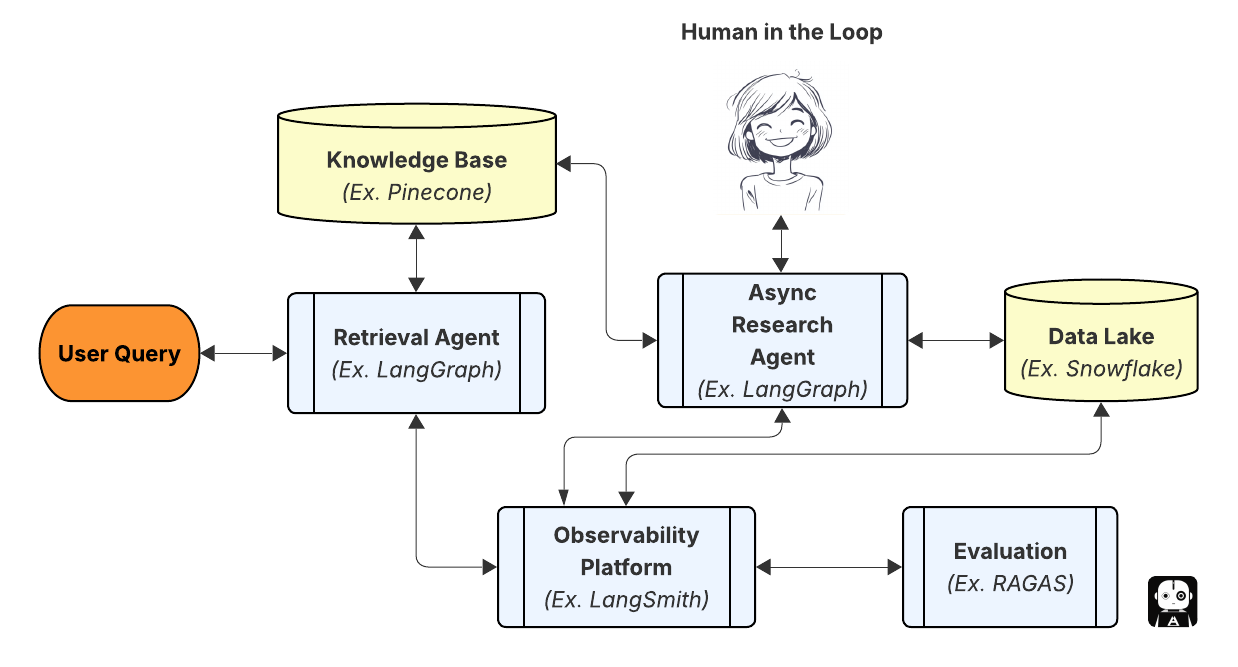
- Build your knowledge base and retrieval. Load your support articles into a vector store (such as Pinecone, Weaviate, or many others) and use LangChain or LangGraph to build a basic retrieval‑augmented generation pipeline. Set your chunking strategy and embedding model; choose a generator (such as GPT‑5) and decide whether to implement state‑machine logic for self‑reflection.
- Instrument for observability. Use LangSmith or Langfuse to trace each query. Log the user input, retrieved contexts, generated answer and any intermediate agent steps. Attach a RAGAS evaluator chain to compute faithfulness, answer relevancy, context recall and context precision .
- Capture signals of success and failure. Combine automatic metrics with explicit user feedback (thumbs up/down or follow‑up questions). Low faithfulness or context recall scores indicate missing or irrelevant context; low answer relevancy suggests the generator misunderstood the question or drifted off topic.
- Trigger async improvement actions. For failures, route the query to a human support agent or an async research agent. The agent can search external sources, compile the correct answer and add it to the knowledge base. At the same time, generate a corrective instruction summarizing the key takeaway (“If asked about contract terms, quote the policy document and don’t speculate”) and store it in the retrieval database . For successes, add the Q&A to your few‑shot example library so the model can learn from itself.
- Improve retrieval and prompts. Analyze patterns in your logs. If context precision is low, try re‑chunking your documents, using a better embedding model or adding a keyword‑based retriever. Use LangGraph to include conditional branches: if retrieval confidence is low, trigger a web search or a different knowledge base. Update your system prompts to reflect lessons learned (e.g., “If unsure, ask follow‑up questions instead of guessing”).
- Repeat and scale. Periodically re‑run the system on a test dataset to track improvements and detect regressions. Use the analytics dashboards in LangSmith or Langfuse to watch how average scores change over time and to ensure new knowledge entries improve rather than degrade performance.
Choosing Your Stack
You don’t need to use every tool mentioned here, but choosing the right components will make your life easier. LangChain gives you building blocks for RAG and agents. LangGraph provides the state‑machine abstraction that makes self‑reflective RAG easy to implement . RAGAS offers RAG‑specific metrics that diagnose retrieval and generation problems . LangSmith integrates those metrics and gives you a GUI for tests and experiments . LangFuse offers a self‑hosted alternative with flexible tracing and analytics . Use whichever fits your budget and privacy requirements.
Final Thoughts
Agentic RAG systems promise more than just retrieving documents: they aim to build an ever‑improving assistant. By instrumenting your pipeline, measuring what matters and acting on the feedback, your customer‑support bot will get smarter with every question. You don’t need to fine‑tune a model to achieve this; you just need to close the loop between retrieval, generation, evaluation and improvement. In an era where AI strategies can easily derail, the teams that iterate quickly and anchor their solutions to user feedback will turn their experiments into lasting advantages .